Big Data Science at Johns Hopkins
Last year Johns Hopkins University (JHU) started the Institute for Data Intensive Engineering and Science (IDIES, pronounced as “Ideas”), promoting the use of large data sets for scientific discovery across the whole university. IDIES spans the Schools of Arts and Sciences, Engineering, Public Health, and Medicine. Hopkins president Ron Daniels and several deans have dedicated 10 new faculty positions to IDIES, all encouraging interdisciplinary research related to Big Data in science. Currently, IDIES has more than 80 faculty associates.
A prominent data-intensive science project at JHU is the public archive of the Sloan Digital Sky Survey (SDSS), one of the world’s largest astronomy databases. Besides the professional astronomy community, the data has been accessed from more than 4 million distinct IP addresses since its creation in 2001. The SDSS data resulted in more than 5,000 refereed publications and over 200,000 citations. The system has a collaborative server-side workspace, CASJOBS, which enables users to save and share their results close to the main database. This system, aimed at the professional astronomy community, is used by more than 6,000 people world-wide. The database can be navigated via an interactive visual interface or accessed programmatically through a web-services API (Figure 1). The database has now grown to 15 Terabytes and all the archived SDSS data exceeds 200 Terabytes.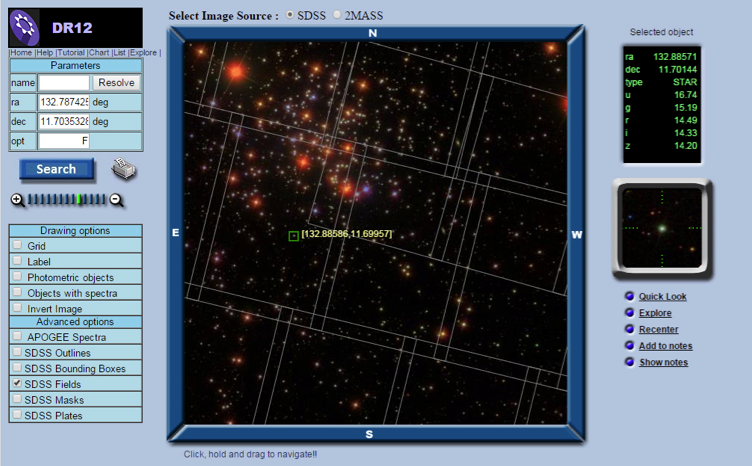
Figure 1: The interactive Navigation tool of the SDSS SkyServer database. The users can access all information in the database through visual navigation.
Beyond astronomy, IDIES has successfully expanded its activities in many other areas of science. For example, members of IDIES have built the Turbulence database [JHTDB], which contains simulations of turbulent flows spanning more than 200TB. To explore this data, JHU scientists have created a novel interface: instead of downloading the prohibitively large simulation files, scientists can launch “virtual sensors” from their laptop, which can either stay fixed or move with the flow, and report back various physical quantities, like velocity, vorticity, pressure, dissipation rate, etc. Over the last 5 years more than a 50 refereed papers have used the data, and launched more than 12 trillion (!) sensors (Figure 2). The ease of access to such large-scale simulation data is helping democratize computational turbulence research. Scientists and engineers who before could not experiment with such datasets due to their size can now easily ask relevant questions. Users range from mathematicians asking questions about near singularities in the partial differential equations that govern fluid flow, to experimentalists who wish to test measurement techniques in ideally controlled flow conditions.
In general, supercomputers are generating ever-larger simulations, but data sets in the hundreds of terabytes often sit unused because they are simply too large to manipulate. Learning from the turbulence experience, IDIES is now turning such simulations into public, open numerical laboratories in other areas of science from cosmological N-body simulations to ocean circulation models. JHU scientists have helped to build the world’s most-used database for cosmological simulations, the Millennium, hosted at the Max Planck Institute in Garching, Germany.
Another fast-growing area of data science research is neuroscience, which has emerged as a national interest area with the US President’s Office announcing the $100M BRAIN initiative in April 2013. IDIES’ Open Connectome Project (OCP) is a leader in data management and analytics for big data neuroscience. The site provides public access to more than 200 TB of neuroscience imaging data from multiple imaging modalities that capture the structure (e.g., electron microscopy, CLARITY and array tomography) and function (e.g., two-photon calcium imaging and fMRI) of the brain. This includes the largest public brain dataset− 20 Teravoxels of the mouse visual cortex that resolve single synapses. OCP connects datasets to computer vision pipelines on supercomputers that reconstructs the structure and connectivity of the brain and stores them in co-registered databases (Figure 3). Neuroscience is poised at the edge of a revolution of discovery based on recent advances in high-throughput imaging. Data-intensive science will help us understand the mechanisms for computation in the human brain and provide the foundation for research into the neurological basis of complex disorders such as autism and ADHD.
Genome sequence data is growing much faster than many other areas in science, thanks to breakthroughs in sequencing technology that make it possible to sequence a human genome in just two days. IDIES scientists today hold more than 2,000 full genomes in house, which have been collected to explore the genetic causes of common diseases including asthma and cancer. Genomics researchers can be found in each of the participating schools of IDIES, and JHU scientists are engaged not only in generating and using sequence data, but also in developing new computational and statistical methods for sequence analysis. For example, one of the most widely used experimental paradigms is RNA sequencing (“RNA-seq”), a technique that allows scientists to study the complex patterns of gene expression in different cells and tissues, and to discover genes whose activity is linked to disease. Hopkins faculty and their students have developed software systems for RNA-seq analysis that have become the standard for the field, used daily in thousands of laboratories around the world.
Johns Hopkins is investing heavily in personalized medicine, exploring new uses of digital information to create individual treatments, and how clinical data can be more efficiently used in translational medicine. For example, OncoSpace, a project integrating a variety of radiation oncology data was built from the elements of the SDSS database. Now it is introduced in clinical use across several universities, it is well on its way to demonstrate how interactive databases can help personalizing complex treatments.
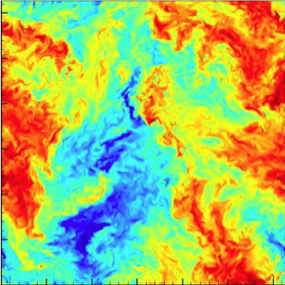
Figure 2: Color contours representing velocity on a 2D slice through the 4D turbulent dataset available at JHTDB. |

Figure 3: Dense reconstruction of the wiring (dendrites and axons) of a mouse visual cortex. |

Figure 4: The JHU-based Data-Scope, with its 10PB of storage and 0.5Tbytes/sec I/O performance. |
The JHU Sheridan Libraries are running the Data Conservancy, originally started by an NSF grant, a project focusing on long term curation of digital collections. The Data Conservancy community and software incorporates lessons learned from over a decade of experience with archiving the SDSS data. Data Conservancy infrastructure design and architecture is based on the Open Archival Information System (OAIS) reference model developed initially by the space sciences community. This architecture accounts for the potential use of high-performance computing over data within an archive. Through a comprehensive information and library science research agenda, Data Conservancy now incorporates requirements from a range of disciplines including the “long-tail” of scientific data. In addition to supporting the functionality of other data repositories or archives, Data Conservancy software also includes a packaging tool based on the community standard BagIt format and the ability to generate and preserve Open Archives Initiative-Object Reuse and Exchange information graphs that connect data and publications and the associated provenance chains. This comprehensive approach has resulted in a data archive platform well suited for a range of scientific data formats and types.
The NSF has awarded several grants to JHU to improve the data-intensive capabilities on campus. First, JHU built the Data-Scope, a 10PB data supercomputer with 100 GPU cards, and a 500Gbytes/sec I/O bandwidth. In collaboration with the Mid-Atlantic Crossroads (MAX), JHU was among the first universities in the world to have 100G data connectivity. Recently, IDIES was awarded a $9.5M grant by the NSF DIBBs program to build more generally usable building blocks from elements of the SDSS archive. This new project, the SciServer, is well along the way to integrate management of the different data sets from astronomy to turbulence, connectomics and genomics, using economies of scale to serve large public collections of scientific data. In collaboration with the University of Maryland, College Park, JHU IDIES is close to completing a shared computational facility, hosted at the Bayview campus of JHU. The system, the Mid-Atlantic Research Computing Consortium (MARCC) will have more than 16,000 cores, about 100 Kepler K80 units and 20 petabytes of disk space. It will be connected to the two campuses and to Internet2 through a 100G connection.
Recently IDIES has awarded nine seed grants to jumpstart an effort in new areas, such as material science, urban planning, combining machine learning with molecular dynamics simulations.
Several new classes are designed in data science, and soon there will be a new data science concentration offered as part of the standard curriculum in the Whiting School of Engineering. Faculty in Biostatistics have created an immensely popular Coursera class in Data Science, with more than a million registered students.
The emergence of Big Data has a transformational role in research. Data driven discoveries are becoming the new “Fourth Paradigm” of science. It is clear that universities are well on the way to respond to these new challenges. IDIES scientists are working very hard to build multidisciplinary collaborations and create new, innovative projects at the frontier of the Science of Big Data.
Links:
[JHTDB] http://turbulence.pha.jhu.edu
[SDSS] http://skyserver.sdss.org
[IDIES] http://idies.jhu.edu/