
Intersectional Analysis of Exposure to Programming Languages Reveals the Additive Impact of Belonging to Multiple Underrepresented Populations
In last month’s CERP infographic for CRN, Senior Research Associate Evelyn Yarzebinski presented data showing that students from populations underrepresented in computing are less likely than their peers to have learned a programming language prior to college. Furthermore, although such programming experience has been increasing during the past five years among all matriculating college students, the data revealed a persistent gap in experience of about 10% when comparing students from an underrepresented population to their peers.
The current analysis builds on these findings by considering the issue of intersectionality, examining whether exposure to programming languages varies among different populations that are underrepresented in computing, and whether belonging to multiple underrepresented populations has an additive association with learning a programming language. This analysis focuses on three student characteristics in particular: race/ethnicity, gender, and first-generation college student status.
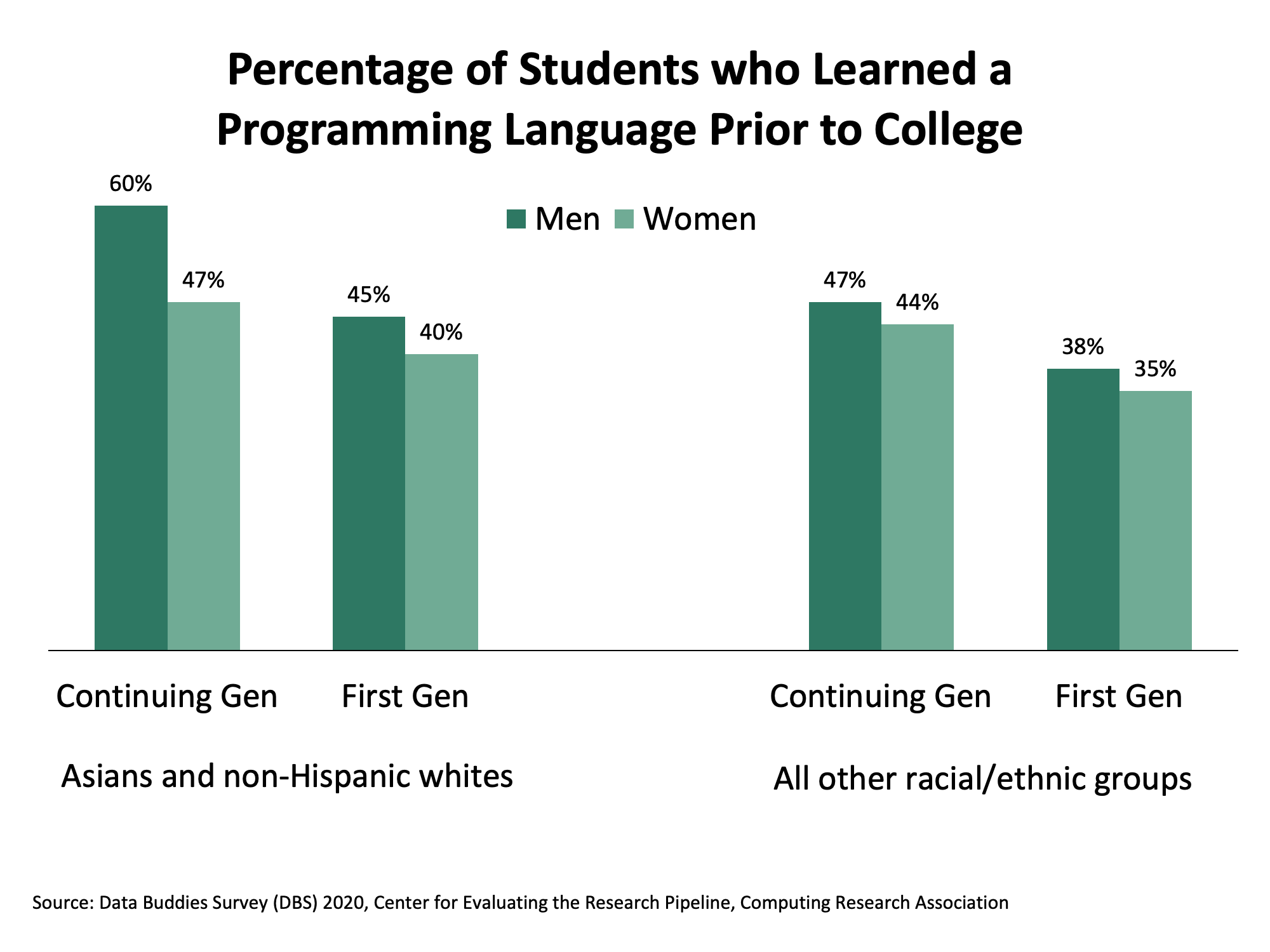
Results showed that each of the three student characteristics examined is significantly associated with the likelihood that a student has learned a programming language prior to college. Overall, men are more likely to have learned a programming language than women, continuing-generation students are more likely to have learned a programming language than first-generation students, and Asian or white students are more likely to have learned a programming language than students from racial/ethnic populations that are underrepresented in computing (i.e., Black/African American, Hispanic/Latinx, Alaskan Native, Native Hawaiian, and/or Pacific Islander students).
Additionally, the likelihood of pre-college exposure to a programming language decreases as students’ membership in different underrepresented populations increases. Those who are not members of any of the examined underrepresented populations — Asian and white men who are continuing-generation college students – have the highest likelihood (60%) of starting college having already learned a programming language. In turn, students who are members of only one underrepresented population are also significantly more likely to have learned a programming language than their peers who are members of two or three underrepresented populations. Notably, comparisons of those who are in none of the three underrepresented populations versus those who are in all of them revealed a substantial gap in programming experience – a 25% difference between the two groups’ reports.
These findings underscore the utility of reporting computing-related data that simultaneously examine multiple identities – such as gender, race/ethnicity, and socioeconomic factors – to gain a more nuanced understanding of the experiences and needs that computing students have at college entry and throughout their computing careers.
Notes:
The survey data analyzed for this infographic were collected by the Center for Evaluating the Research Pipeline via The Data Buddies Project. The sample includes 9,228 undergraduates from the 2020 Data Buddies Survey who provided demographic information on their race/ethnicity, gender, first- or continuing-generation student status, and indicated whether they had learned a new programming language prior to entering an undergraduate program. For this analysis, students from underrepresented populations were defined as being women, first-generation students, and/or Black/African American, Hispanic/Latinx, Alaskan Native, Native, Hawaiian, and/or Pacific Islander students. Notably, this analysis differs from the previous month’s analysis in that: (1) it does not include disability status; and (2) it does not separate students by matriculation year. Z-tests were conducted for each of the student characteristics examined – race/ethnicity (Asian or white versus all others), gender (women versus men) and first-generation status (first- or continuing-generation). Each was statistically significant at p < .05. In addition, a summary score of the number of underrepresented populations each student belonged to was calculated, with scores ranging from 0 to 3. Z-tests revealed the following significant group differences (p < .05): 0 groups > 1 group > (2 groups = 3 groups).
 This analysis is brought to you by the CRA’s Center for Evaluating the Research Pipeline (CERP). CERP provides social science research and comparative evaluation for the computing community. Subscribe to the CERP newsletter here. Volunteer for Data Buddies by signing up here.
This analysis is brought to you by the CRA’s Center for Evaluating the Research Pipeline (CERP). CERP provides social science research and comparative evaluation for the computing community. Subscribe to the CERP newsletter here. Volunteer for Data Buddies by signing up here.
The Data Buddies Project is currently supported through National Science Foundation (NSF) awards CNS-1840724, CNS-2036717, DUE-1821136, sub-awards and contracts, and direct CRA contributions. Previous NSF awards that supported DBS include CNS-1246649 and DUE-1431112. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.





