
CCC @ AAAS 2020 – New Approaches to Fairness in Automated Decision Making

Jaime Morgenstern

Sampath Kannan
The last decade has seen the increased use of machine learning and data science to make decisions—from figuring out which YouTube video to recommend to deciding whom to give a loan, automated decisions are now everywhere. However, as deployment of these decision-making systems has increased so too have concerns about the transparency of the component algorithms and the fairness of their outcomes. This topic was the subject of the New Approaches to Fairness in Automated Decision Making scientific session at the 2020 American Association for the Advancement of Science (AAAS) Annual meeting in Seattle, Washington one month ago.

Toniann Pitassi

Moritz Hardt
The session was moderated by Computing Community Consortium (CCC) Director Ann Schwartz Drobnis and included:
- Sampath Kannan (University of Pennsylvania) who explained the basics of machine learning (ML) and why fairness (or a lack there of) is a concern in the use of ML-based systems in his presentation Decision Making by Machine Learning Algorithms;
- Moritz Hardt (UC Berkeley) who discussed the different possible goals of fairness and how algorithms should be designed to meet these goals in his presentation New Approaches to Fairness in Automated Decision Making;
- Toniann Pitassi (University of Toronto) who demonstrated a mathematical definition of fair classification and reviewed the tradeoffs to pursuing different kinds of fairness in her presentation Recognizing and Overcoming Frictions to Fairness;
- and Jamie Morgenstern (University of Washington) as the discussant, who tied together the concerns raised in the three talks and led the Q&A.
As an example of the impact of bias in automated systems, Sampath Kannan highlighted a now discontinued Amazon hiring tool that discriminated against women applying to technical jobs.[1] Amazon’s model was based on data from the previous ten years of hiring and these hires had been predominantly men.
Why Amazon’s Automated Hiring Tool Discriminated Against Women”
Subsequently the hiring software “learned” to favor men over women, and the system “penalized resumes that included the word “women’s,” as in “women’s chess club captain” and lowered the rankings of graduates from two all-women’s colleges.[2] In order to counter these effects, Kannan argued, we must be aware of potential data feedback loops. We must also recognize that algorithms trained on minority populations might be less accurate due to a lack of data. Algorithms may need to explicitly take into account group membership in order to be fair. In any case, forbidding an algorithm to use sensitive attributes like minority status does not work because there may still be proxy variables that correspond to this status (e.g. zip code as a proxy for race).
Building off of this idea, Moritz Hardt opened his talk with a quote from physicist, Ursula Franklin, who said: “[T]echnologies are developed and used within a particular social, economic, and political context. They arise out of a social structure, they are grafted on to it, and they may reinforce it or destroy it, often in ways that are neither foreseen nor foreseeable.” Franklin was speaking in the 80s but the sentiment applies to modern ML-based systems—the state of the world influences the measurements and data from which the model learns, the model will then influence individuals and the state of the world, this will in turn loop back around to influence the measurement and data once again.
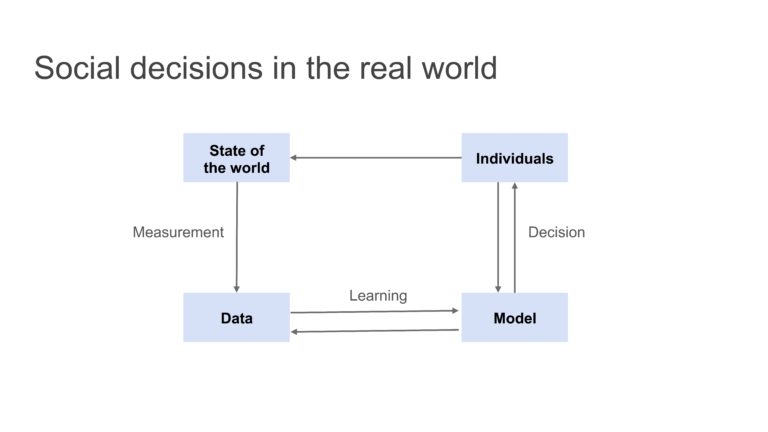
The impact of social decisions in the real world.
As an example of the influence of society on causality, Hardt discussed the discrepancy between men and women’s admission rates to University of California, Berkeley graduate schools in 1973. This might seem oddly specific but is the subject of a famous paper on sex bias by Bickel, Hammel, and O’Connell (see footnote)[3]. Among the top six departments at UC Berkeley in 1973, the male acceptance rate was 44% and the female acceptance rate was 30%. However when examined on a department by department level the acceptance rate of women was generally about the same as the acceptance rate of men. What then caused this discrepancy?
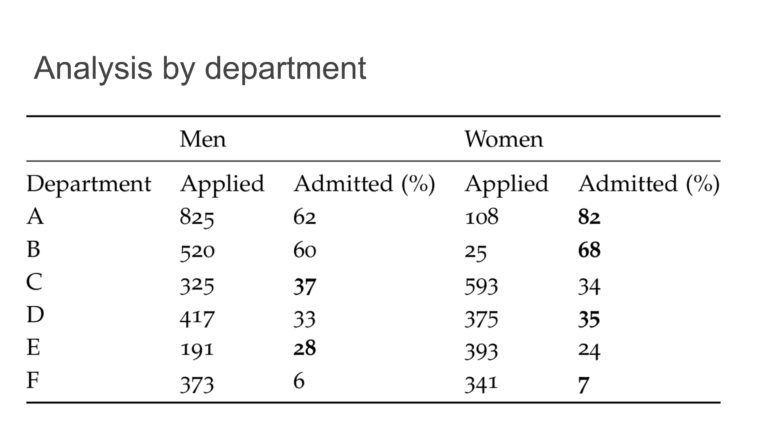
Admission rates to University of California, Berkeley graduate schools in 1973.
Bickel’s explanation was that “The bias in the aggregated data stems not from any pattern of discrimination on the part of admissions committees, which seems quite fair on the whole, but apparently from prior screening at earlier levels of the educational system. Women are shunted by their socialization and education toward fields of graduate study that are generally more crowded, less productive of completed degrees, and less well funded, and that frequently offer poorer professional employment prospects.”[3] In short, due to prior influences women more frequently applied to departments like humanities, which had greater numbers of applicants and could accept fewer students, than departments like engineering, which had higher budgets, fewer applicants, and could accept a greater number of students. Hardt contended that perpetuating such feedback loops is a major risk of using automated decision making systems and the architects of these systems must be careful to guard against that.
Finally, Toniann Pitassi presented a more mathematical view of fairness. When building a predictive model, for some feature vector, (e.g. test scores), that corresponds to an actual value ofas a function of (e.g. student gets into a certain college), you want to be able to learn a classifier that gives you the predicted value, that is accurate on 99% of the population. Taking fairness into account you also need to ensure that the classifier is “fair” with respect to where is some protected group. Pitassi said that the “most common way to define ‘fair’ is to require some invariance/independence with respect to the sensitive attribute.” Pitassi presented three main ways to define fairness mathematically:
- Demographic parity, ŷ ⊥ A , says that the value of A should not be able to tell you anything about the predicted value, ŷ (e.g. the race of a student should not influence their likelihood of getting into a certain college);
- Equalized odds, ŷ ⊥ A | Y, means that the true positive rate and the false positive rate are the same for both the protected and non-protected group (e.g. an equal amount of “qualified” and “unqualified” students from each demographic get into a certain college);
- And equalized calibration, Y ⊥ A | ŷ, is the condition where outcomes are independent of protected attributes (e.g. the percentage of students who achieve the necessary test scores and then get into a certain college should be same across demographics).
Unfortunately, these three definitions are generally incompatible outside of nontrivial cases—you cannot have equalized odds and equalized calibration simultaneously; therefore, a conscious decision must be made when designing algorithms on which kind of fairness is appropriate for the model in questions.

Is the classifier biased?

COMPAS risk assessment program was concluded to be biased by Propublica.
The Q&A offered attendees of the session the opportunity to hear more from the speakers. One question, asked by a software engineer, addressed the economic incentives for fairness. The attendee asked, “What is the business argument for testing fairness in software development when your primary priority is profits?” In response, Jamie Morgenstern replied that if your product doesn’t work well for a certain population then your product doesn’t work. This should be viewed as an opportunity to improve you product and make it useable, and therefore more profitable, for a broader population.
View all the slides and learn more about the “New Approaches to Fairness in Automated Decision Making” session on the CCC @ AAAS webpage.
Related Links:
- Learning Adversarially Fair and Transferable Representations, Toniann Pitassi et al. https://www.cs.toronto.edu/~toni/Papers/laftr.pdf
- Algorithmic and Economic Perspectives on Fairness, CCC workshop report https://cra.org/ccc/wp-content/uploads/sites/2/2019/01/Algorithmic-and-Economic-Perspectives-on-Fairness.pdf
- The Frontiers of Fairness in Machine Learning, CCC workshop report https://cra.org/ccc/wp-content/uploads/sites/2/2018/01/The-Frontiers-of-Fairness-in-Machine-Learning.pdf
- Privacy-Preserving Data Analysis for the Federal Statistical Agencies, CCC white paper https://cra.org/ccc/wp-content/uploads/sites/2/2015/01/CCCPrivacyTaskForcePaperRevised-FINAL.pdf
- Towards a Privacy Research Roadmap for the Computing Community, CCC white paper https://cra.org/ccc/wp-content/uploads/sites/2/2015/01/CCC-National-Privacy-Research-Strategy.pdf
- Big Data, Data Science, and Civil Rights, CCC white paper https://cra.org/ccc/wp-content/uploads/sites/2/2017/06/BigDataDataScienceandCivilRights-v6.pdf
- Afternoon Session: Individuals, Groups, Pattern Recognition and Rich Data, Simons Institute via Youtube: https://www.youtube.com/watch?v=7roIh-SrBAo
- The ethical algorithm, Brookings Institute via Youtube: https://www.youtube.com/watch?v=PvUOMaBf9X4&feature=emb_title
[1] Rachel Goodman, “Why Amazon’s Automated Hiring Tool Discriminated Against Women,” ACLU Blog, 2018. https://www.aclu.org/blog/womens-rights/womens-rights-workplace/why-amazons-automated-hiring-tool-discriminated-against
[2] Jeffrey Dastin, “Amazon scraps secret AI recruiting tool that showed bias against women,” Reuters, 2018.https://www.reuters.com/article/us-amazon-com-jobs-automation-insight/amazon-scraps-secret-ai-recruiting-tool-that-showed-bias-against-women-idUSKCN1MK08G
[3] P. J. Bickel, E. A. Hammel, J. W. O’Connell, Sex Bias in Graduate Admissions: Data from Berkeley, 1975. https://pdfs.semanticscholar.org/b704/3d57d399bd28b2d3e84fb9d342a307472458.pdf





